Scanner inteligente
Este é um projeto proposto para a conclusão da disciplina de Processamento Digital de Imagens - UFRN, referente ao semestre de 2022.1. Neste projeto, criaremos um scanner de documentos simples usando o OpenCV, realizando o processamento em tempo real e o salvamento dessas imagens a partir de um comando do teclado.
Para a implementação do algoritmo, importaremos as seguintes bibliotecas:
import cv2
import sys
import numpy as np
import pytesseractO módulo cv2 importa os métodos do OpenCV para possibilitar o processamento, detecção e reconhecimento de imagens, necessárias à aplicação. O módulo sys fornece acesso a parâmetros e funções específicas do sistema. Já o módulo numpy será utilizado em rotinas para processar arrays e cálculos númericos demandados. Por fim, o módulo pytesseract é a ferramenta óptica de reconhecimento de caracteres (OCR), a qual é responsável por identificar o texto incorporado nas imagens.
Inicialmente, criamos a janela e a barra de ajuste que controlará o threshold do algoritmo de Canny por meio da função cv2.createTrackbar().
cv2.namedWindow('bordas')
cv2.createTrackbar('threshold', 'bordas', 100, 250, on_trackbar_canny)
on_trackbar_canny(100)Dessa forma, define-se um slider que pode assumir valores entre 0 e 250. Um dos parâmetros exigidos para esta criação é uma função de callback, a qual será chamada sempre que o usuário interagir com a barra de rolagem. Esta função foi definida por on_trackbar_canny, que possui um argumento (val), mas este não é utilizado em seu interior.
Define-se manualmente a variável path para a configuração do módulo pytesseract no Windows.
pytesseract.pytesseract.tesseract_cmd = 'C:\\Program Files\\Tesseract-OCR\\tesseract.exe'Em seguida, faremos a inicialização das variáveis booleanas camera e pause, além das dimensões h (height) e w (width), que serão utilizadas para compor a imagem de saída, preservando a proporção comumente observada em folhas de papel.
camera = True
pause = False
h, w = 1574, 1240O scanner pode extrair textos de arquivos de imagem ou captura de vídeo. Nesse sentido, tenta-se inicializar uma entrada de vídeo. Caso a abertura da câmera não seja possível, carrega-se uma imagem para processamento, convertendo-a para tons de cinza e aplicando borramento através de um filtro gaussiano 5x5, definido na função cv2.GaussianBlur(). Caso não haja abertura de nenhuma fonte de imagem, o programa é encerrado.
cap = cv2.VideoCapture(1, cv2.CAP_DSHOW)
if not cap.isOpened():
print("Câmera não encontrada.")
camera = False
arquivo = 'papel.jpg'
image = cv2.imread(arquivo, cv2.IMREAD_COLOR)
orig_h, orig_w = image.shape[:-1]
image_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred_image = cv2.GaussianBlur(image_gray, (5, 5), 1)
if not image.data:
print('Erro ao abrir a câmera e carregar o arquivo.')
sys.exit() # encerra o programaPara o caso de inicialização de um dispositivo de captura de vídeo, rotacionamos cada frame em 90° devido à natureza das imagens enviadas pela câmera utilizada, armazenamos o tamanho do frame e aplicamos a mesma conversão e filtragem supracitadas.
Assim, aplicaremos o detector de bordas pelo método de Canny. Fazendo uso da função cv2.Canny(), são detectados as bordas da imagem são destacadas gerando uma imagem binária. É válido salientar que, o limiar \(T_1\) empregado é determinado a partir da interação do usuário com o slider, enquanto o \(T_2\) é obtido considerando a proporção de 3:1.
threshold1 = cv2.getTrackbarPos('threshold', 'bordas')
bordas = cv2.Canny(image, threshold1, 3*threshold1)
Em seguida, aplica-se operações de morfologia matemática (dilatação e fechamento) na imagem binária gerada a fim de fundir possíveis descontinuidades e engrossar os contornos, facilitando a sua detecção. Para tal, cria-se um elemento estruturante retangular 3x3 por meio da função cv2.getStructuringElement().
element = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
bordas = cv2.dilate(bordas, element, iterations=1)
bordas = cv2.morphologyEx(bordas, cv2.MORPH_CLOSE, element)Dessa maneira, o algoritmo procurará todos os contornos externos por meio da função cv2.findContours() com o uso do parâmetro cv2.RETR_EXTERNAL.
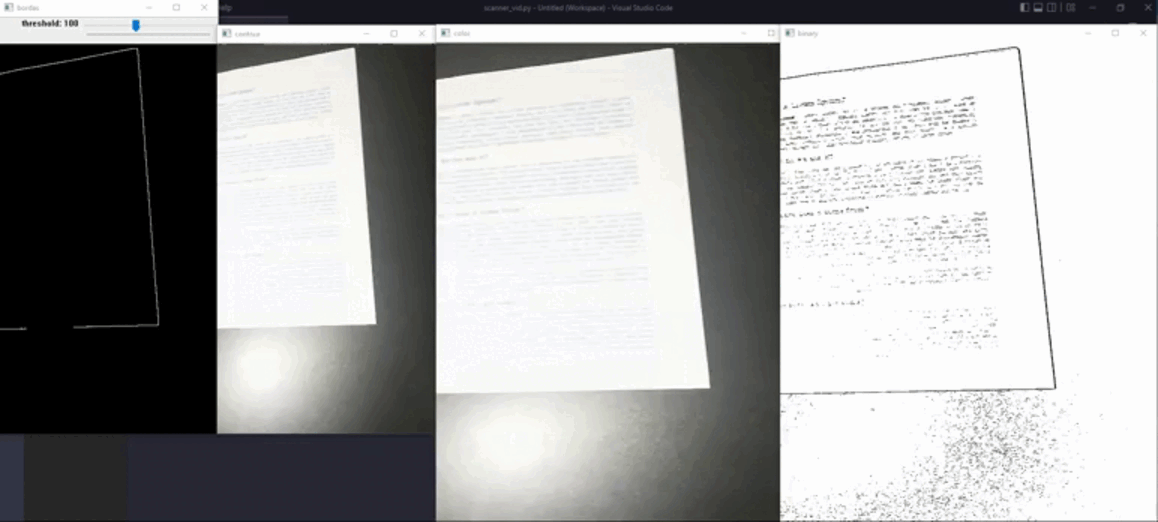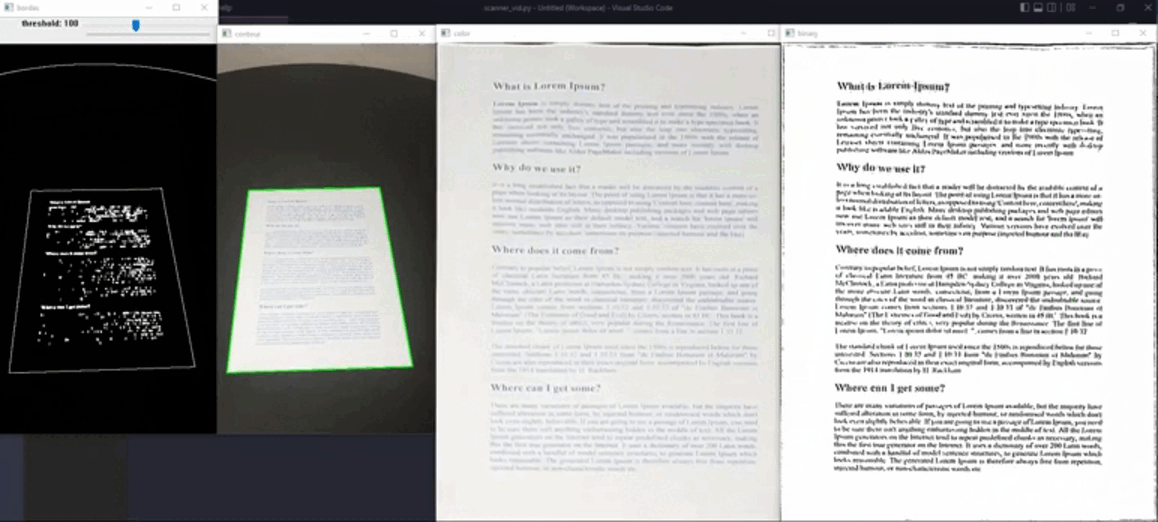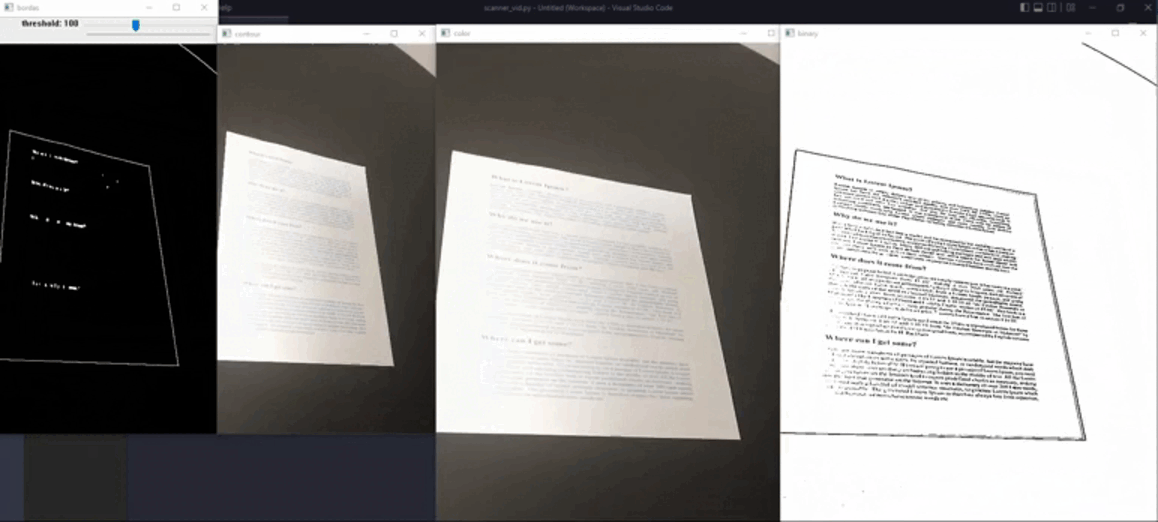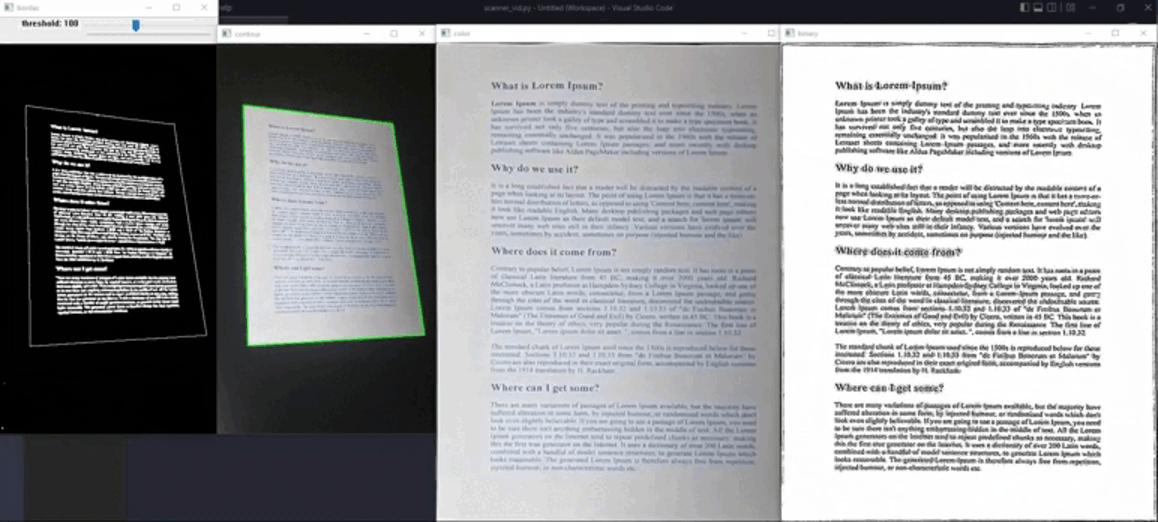
contours, _ = cv2.findContours(bordas, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)Nesse momento, identifica-se o maior contorno com os pontos de canto. Este será considerado como o contorno que delimita o papel/documento/quadro onde está o texto de interesse. A função find_paper() detecta o contorno de maior área e aproxima este por um polígono de quatro lados utilizando a função cv2.approxPolyDP().
def find_paper(cntrs):
aux = list(cntrs)
if len(aux) > 0:
aux.sort(reverse=True, key=lambda x: cv2.contourArea(x))
perimeter = cv2.arcLength(aux[0], True)
polygon = cv2.approxPolyDP(aux[0], 0.04*perimeter, True)
return polygon
else:
return auxA imagem abaixo exibe o resultado obtido nesse processo.

A função sort_points() é responsável por reorganizar a ordem dos pontos definidos como os cantos do papel para corresponder às quinas da imagem, o que é feito considerando a soma e diferença entre as coordenadas.
def sort_points(pts):
pts = pts.reshape(4, 2)
temp = np.zeros((4, 1, 2), dtype=np.float32)
soma = pts.sum(1)
dif = np.diff(pts, axis=1)
# para corresponder ao [0,0], buscamos o ponto com menor soma entre as coordenadas
temp[0] = pts[np.argmin(soma)]
# para o [largura-1,haltura-1], buscamos o ponto com a maior soma
temp[3] = pts[np.argmax(soma)]
# para o [largura-1,0], buscamos o ponto com a menor diferença entre as coordenadas
temp[1] = pts[np.argmin(dif)]
# para o [0,altura-1], buscamos o ponto com a a maior diferença
temp[2] = pts[np.argmax(dif)]
return tempCriaremos, após reorgnização dos pontos, a nossa matriz de transformação para, enfim, aplicarmos uma mudança de perspectiva na imagem. O objetivo é ter uma visão frontal do documento para melhor reconhecimento/processamento do conjunto de símbolos dispostos (palavras e pontuações).
if len(paper) == 4:
cv2.drawContours(img_contour, [paper], -1, (0, 255, 0), 5)
points = sort_points(paper)
new_points = np.float32([[0, 0], [w-1, 0], [0, h-1], [w-1, h-1]])
# realiza mudança de perspectiva na imagem
transf_matrix = cv2.getPerspectiveTransform(points, new_points)
scanned_color = cv2.warpPerspective(image, transf_matrix, (w, h))
else:
# caso não sejam detectadas as bordas do papel
scanned_color = image.copy()Com mudança de perspectiva, a imagem transformada pode ser observada abaixo:

Aplicaremos, a partir disso, o limiar adaptativo na imagem em tons de cinza, o qual varia no decorrer da figura, para gerar o papel digitalizado e faremos o negativo do resultado, a fim de obter um fundo branco com escrita preta.
scanned_gray = cv2.cvtColor(scanned_color, cv2.COLOR_BGR2GRAY)
scanned_gray = cv2.GaussianBlur(scanned_gray, (5, 5), 1)
adapt_threshold = cv2.adaptiveThreshold(scanned_gray, 255, 1, 1, 7, 2)A Figura 4 mostra a imagem resultante após o procedimento de limiarização.

Ao fim do processamento, utiliza-se a função cv2.imshow() para exibir versões menores das imagens geradas, preservando-se suas proporções. Em resumo, as etapas descritas são reunidas e mostradas na figura abaixo.

Por fim, são estabelecidos os comandos de teclado para encerrar o programa, pausar ou salvar em arquivos. Ao pressionar a tecla esc, o programa para de rodar. Por outro lado, pressionando a tecla p, podemos congelar a imagem capturada enquanto a variável pause for True, funcionando como um preview do resultado para o usuário, para que este decida se deseja concretizar o salvamento ou não.
key = cv2.waitKey(10)
if key == 27:
break # esc pressed!
elif key == ord('p'):
pause = not pause
elif key == ord('s'):
cv2.imwrite('scanned_color.png', scanned_color)
cv2.imwrite('scanned_bin.png', scanned_bin)
write_file('img_text.txt')Já ao pressionar a tecla s, a imagem é salva na escala colorida e em tons de cinza, além de ser exportado o texto escrito e editável em um arquivo .txt, com auxílio da função write_file(). Nela, obtém-se o texto da imagem por meio da função pytesseract.image_to_string() e são realizados alguns tratamentos para retirar o excesso de quebras de linha e corrigir o reconhecimento indevido de alguns caracteres.
def write_file(filename):
def write_file(filename):
text = pytesseract.image_to_string(scanned_bin)
text = text.replace('\n\n', '^\n')
split_text = text.split('\n')
for i, line in enumerate(split_text):
if line[-1:] == '.':
line = line + '\n\n'
elif line[-1:].isalpha() or line[-1:] in [',', '-']:
line = line + ' '
elif line[-1:] in [':', ';']:
line = line + '\n'
split_text[i] = line
new_text = ''.join(split_text)
new_text = new_text.replace('^', '\n\n')
split_text = new_text.split('.')
for i in range(len(split_text)-1):
if len(split_text[i+1]) == 0:
split_text[i+1] = '..'
if len(split_text[i+1]) >= 1:
if split_text[i][-1:].islower() and split_text[i+1][0].islower() :
split_text[i] = split_text[i] + ' '
elif split_text[i][-1:].isnumeric() and split_text[i+1][0].isnumeric():
split_text[i] = split_text[i] + '.'
if len(split_text[i+1]) >= 2:
if (split_text[i+1][0] == ' ' and split_text[i+1][1].isupper()) or split_text[i+1][:1] == '\n':
split_text[i] = split_text[i] + '.'
new_text = ''.join(split_text)
file = open(filename, 'w', encoding='utf-8')
file.write(new_text)
file.close()O resultado do texto extraído no teste está disponível em: img_text.txt.
Visualizamos a seguir a captura de texto atráves de uma câmera em tempo real.
O código completo referente a este projeto pode ser encontrado em: scanner.py.